
Spark SQL
Spark SQL is Apache Spark's module for querying structured data using SQL or a DataFrame API, offering seamless integration and high scalability across various data sources.
 Tags
Tags
 Useful for
Useful for
- 1.What is Spark SQL?
- 2.Features
- 2.1.1. Unified Data Access
- 2.2.2. Integration with Hive
- 2.3.3. Performance Optimization
- 2.4.4. Standard Connectivity
- 2.5.5. Support for DataFrames and Datasets
- 2.6.6. Extensible and Open Source
- 3.Use Cases
- 3.1.1. Data Warehousing
- 3.2.2. Data Transformation and ETL
- 3.3.3. Real-Time Analytics
- 3.4.4. Machine Learning
- 3.5.5. Business Intelligence
- 4.Pricing
- 5.Comparison with Other Tools
- 5.1.1. Performance
- 5.2.2. Scalability
- 5.3.3. Flexibility
- 5.4.4. Language Support
- 5.5.5. Community and Ecosystem
- 6.FAQ
- 6.1.What is the primary use of Spark SQL?
- 6.2.Can I use Spark SQL with existing Hive data?
- 6.3.Is Spark SQL suitable for real-time analytics?
- 6.4.What programming languages are supported by Spark SQL?
- 6.5.Is Spark SQL free to use?
- 6.6.How does Spark SQL compare to traditional databases?
What is Spark SQL?
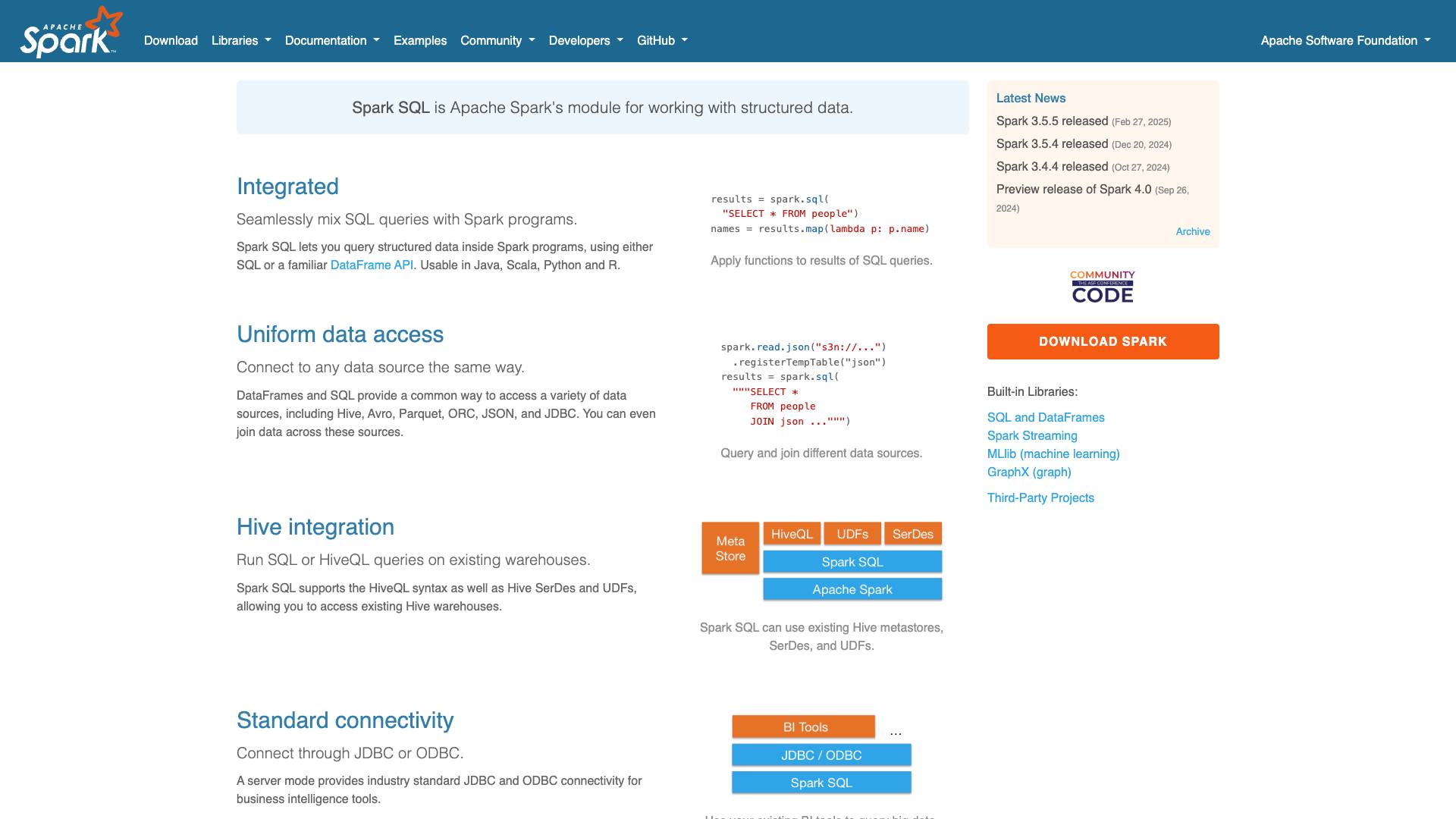
Spark SQL is a powerful module of Apache Spark, designed specifically for working with structured data. It provides a programming interface that allows users to execute SQL queries alongside their Spark programs, utilizing either SQL syntax or a familiar DataFrame API. This integration makes it easier for data analysts and engineers to interact with large datasets using a more intuitive approach, regardless of their background in programming.
With support for multiple programming languages, including Java, Scala, Python, and R, Spark SQL has become an essential tool in the big data ecosystem. It is optimized for speed and scalability, making it suitable for processing massive datasets across distributed computing environments.
Features
Spark SQL is packed with features that enhance its usability and performance. Here are some of the key features:
1. Unified Data Access
Spark SQL allows users to connect to a variety of data sources using a common interface. This includes popular formats such as:
- Hive
- Avro
- Parquet
- ORC
- JSON
- JDBC
This unified access means that users can easily query and join data from multiple sources within a single SQL statement, simplifying complex data retrieval processes.
2. Integration with Hive
One of the standout features of Spark SQL is its seamless integration with Apache Hive. Users can run SQL or HiveQL queries on existing Hive warehouses, leveraging Hive's metastore, SerDes (Serializer/Deserializer), and UDFs (User Defined Functions). This feature allows organizations to utilize their existing Hive infrastructure while benefiting from the performance enhancements that Spark SQL provides.
3. Performance Optimization
Spark SQL includes a cost-based optimizer that significantly enhances query performance. Key performance features include:
- Columnar Storage: This allows data to be stored in a format that optimizes read performance, especially for analytical queries.
- Code Generation: Spark SQL can generate optimized bytecode at runtime, which reduces the overhead of interpreting queries.
- Mid-Query Fault Tolerance: The underlying Spark engine provides full fault tolerance, ensuring that long-running queries can recover from failures without losing progress.
These optimizations make Spark SQL capable of handling complex queries over large datasets efficiently.
4. Standard Connectivity
Spark SQL supports standard connectivity through JDBC and ODBC protocols. This feature enables users to connect their business intelligence (BI) tools directly to Spark SQL, allowing for easy data visualization and reporting. Organizations can leverage their existing BI tools to query big data without needing to switch to different platforms.
5. Support for DataFrames and Datasets
DataFrames are a core abstraction in Spark SQL, representing distributed collections of data organized into named columns. This abstraction allows users to perform operations in a way that is both intuitive and efficient. The DataFrame API provides a rich set of functions for data manipulation, making it easy to perform complex transformations and analyses.
Additionally, Spark SQL introduces Datasets, which combine the benefits of DataFrames with strong typing, enabling compile-time type safety and object-oriented programming.
6. Extensible and Open Source
As part of the Apache Software Foundation, Spark SQL is an open-source project that benefits from a large community of developers. This community-driven approach ensures that Spark SQL is continuously tested, updated, and improved. Users can contribute to the project, report issues, and request features, fostering an environment of collaboration and innovation.
Use Cases
Spark SQL is versatile and can be applied across various industries and use cases. Here are some common scenarios where Spark SQL excels:
1. Data Warehousing
Organizations can utilize Spark SQL to build and manage data warehouses. By integrating with existing Hive warehouses, users can run complex analytical queries on large datasets, enabling better decision-making based on data insights.
2. Data Transformation and ETL
Spark SQL is ideal for Extract, Transform, Load (ETL) processes. Users can read data from various sources, perform transformations using SQL or DataFrame operations, and write the processed data back to storage systems. This capability is essential for preparing data for analytics and reporting.
3. Real-Time Analytics
With its ability to process data in real-time, Spark SQL is well-suited for applications that require immediate insights. Organizations can use Spark SQL to analyze streaming data from sources like IoT devices or social media, allowing them to react quickly to changing conditions.
4. Machine Learning
Spark SQL can be integrated with Spark's MLlib, the machine learning library, to facilitate data preprocessing and feature engineering. Users can leverage SQL queries to prepare datasets for machine learning models, enhancing the efficiency of the model training process.
5. Business Intelligence
By providing standard connectivity through JDBC and ODBC, Spark SQL enables organizations to connect their BI tools directly to big data sources. This capability allows data analysts to create reports and dashboards using familiar tools, making it easier to visualize and understand complex data.
Pricing
Spark SQL is part of the open-source Apache Spark project, which means it is free to use under the Apache License, Version 2.0. Organizations can download and deploy Spark SQL without incurring licensing fees. However, users should consider the costs associated with infrastructure, such as cloud services or on-premises hardware, as well as any potential support or consulting services they may require.
Comparison with Other Tools
When comparing Spark SQL with other data processing and analytics tools, several unique selling points emerge:
1. Performance
Spark SQL is designed for high performance, thanks to its in-memory computing capabilities and optimization features. Compared to traditional databases, Spark SQL can handle large-scale data processing more efficiently, especially for complex analytical queries.
2. Scalability
Spark SQL is built on the Spark engine, which is known for its ability to scale horizontally across thousands of nodes. This scalability makes it suitable for handling massive datasets that would be challenging for other tools to process effectively.
3. Flexibility
Unlike some other SQL engines that are tied to specific data sources or formats, Spark SQL offers a unified interface for accessing various data sources. This flexibility allows users to work with diverse datasets without needing to change their querying approach.
4. Language Support
Spark SQL supports multiple programming languages, including Java, Scala, Python, and R. This multi-language support makes it accessible to a broader audience, allowing data professionals to use the tools and languages they are most comfortable with.
5. Community and Ecosystem
Being part of the Apache Software Foundation, Spark SQL benefits from a large and active community. This community support leads to continuous improvement, regular updates, and a wealth of resources for users, including documentation, tutorials, and forums for discussion.
FAQ
What is the primary use of Spark SQL?
The primary use of Spark SQL is to work with structured data, allowing users to run SQL queries and perform data manipulations using the DataFrame API. It is commonly used for data warehousing, ETL processes, real-time analytics, and integrating with BI tools.
Can I use Spark SQL with existing Hive data?
Yes, Spark SQL integrates seamlessly with Apache Hive, allowing users to run SQL or HiveQL queries on existing Hive warehouses. This integration enables organizations to leverage their existing Hive infrastructure while benefiting from Spark SQL's performance enhancements.
Is Spark SQL suitable for real-time analytics?
Yes, Spark SQL can process streaming data in real-time, making it suitable for applications that require immediate insights. Organizations can analyze data from sources such as IoT devices or social media in real-time using Spark SQL.
What programming languages are supported by Spark SQL?
Spark SQL supports multiple programming languages, including Java, Scala, Python, and R. This multi-language support makes it accessible to a wide range of data professionals.
Is Spark SQL free to use?
Yes, Spark SQL is an open-source project that is free to use under the Apache License, Version 2.0. However, users should consider infrastructure costs and any potential support services they may need.
How does Spark SQL compare to traditional databases?
Spark SQL is designed for high performance and scalability, making it suitable for large-scale data processing. Unlike traditional databases, Spark SQL can handle complex analytical queries efficiently and provides a unified interface for accessing various data sources.
In conclusion, Spark SQL is a versatile and powerful tool for working with structured data, offering a range of features that enhance its usability and performance. Its integration with Hive, support for multiple programming languages, and ability to connect to various data sources make it a valuable asset in the big data ecosystem. Whether for data warehousing, real-time analytics, or business intelligence, Spark SQL provides the tools necessary for effective data analysis and decision-making.
Ready to try it out?
Go to Spark SQL