
GloVe
GloVe is a powerful word embedding tool that captures global word-word statistical information for enhanced natural language processing.
 Tags
Tags
 Useful for
Useful for
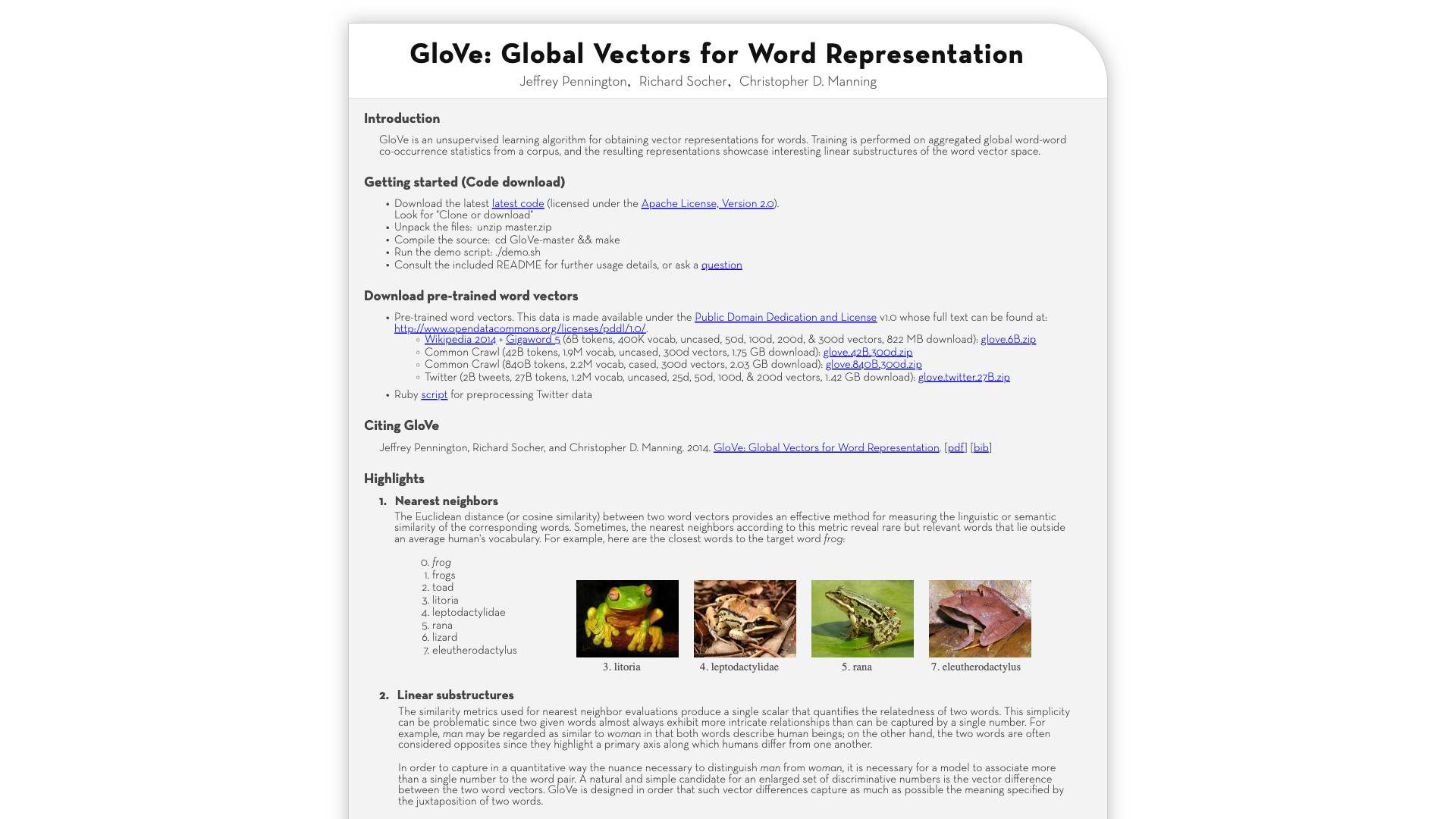
- 1.What is GloVe?
- 2.Features
- 3.Use Cases
- 4.Pricing
- 5.Comparison with Other Tools
- 5.1.Key Differences
- 6.FAQ
- 6.1.What kind of data can I use to train GloVe?
- 6.2.How do I use pre-trained GloVe models?
- 6.3.Can I train GloVe on my own dataset?
- 6.4.Is GloVe suitable for real-time applications?
- 6.5.What are the limitations of GloVe?
- 6.6.How does GloVe handle polysemy (words with multiple meanings)?
- 6.7.Can GloVe be used for languages other than English?
What is GloVe?
GloVe, which stands for Global Vectors for Word Representation, is an unsupervised learning algorithm designed to produce word embeddings. Developed by researchers at Stanford University, GloVe captures the meaning of words based on their context and co-occurrence in a large corpus of text. Unlike traditional word embedding techniques that rely solely on local context (like Word2Vec), GloVe leverages global statistical information, allowing it to create dense vector representations that encapsulate semantic relationships between words.
The primary goal of GloVe is to provide a more nuanced understanding of the relationships between words by representing them as points in a high-dimensional space. The closer two words are in this space, the more semantically similar they are. This capability makes GloVe a powerful tool in various natural language processing (NLP) tasks.
Features
GloVe comes with a variety of features that make it a robust choice for generating word embeddings:
-
Global Co-occurrence Matrix: GloVe constructs a co-occurrence matrix that captures how frequently words appear together in a corpus. This matrix is central to understanding the relationships between words.
-
Dimensionality Reduction: The algorithm reduces the high-dimensional co-occurrence matrix to a lower-dimensional space, creating dense word vectors that are computationally efficient and easier to work with.
-
Semantic Similarity: GloVe embeddings enable the identification of semantic similarities between words. For instance, the relationship between "king" and "queen" can be captured in the vector space, allowing for analogies like "king - man + woman = queen."
-
Ease of Use: GloVe is designed to be user-friendly, with straightforward implementations available in various programming languages, including Python and Java.
-
Pre-trained Models: GloVe offers pre-trained models on large datasets, which can be directly used for various applications without the need for extensive training.
-
Customizability: Users can train GloVe on their own datasets, allowing for tailored embeddings that reflect specific domains or contexts.
-
Support for Multiple Languages: GloVe can be trained on multilingual datasets, making it suitable for applications in various languages.
Use Cases
GloVe has a wide range of applications across different fields, particularly in natural language processing and machine learning. Some common use cases include:
-
Text Classification: GloVe embeddings can be used as input features for machine learning models to classify text into predefined categories, such as sentiment analysis or topic classification.
-
Information Retrieval: By representing documents and queries as vectors, GloVe facilitates improved search and retrieval systems, allowing for more relevant results based on semantic similarity.
-
Recommendation Systems: GloVe can enhance recommendation algorithms by providing context-aware embeddings that improve user-item matching based on textual descriptions.
-
Chatbots and Virtual Assistants: In conversational AI, GloVe embeddings help understand user intent and generate more contextually relevant responses.
-
Machine Translation: GloVe can assist in translating text by capturing the semantic relationships between words in different languages.
-
Named Entity Recognition: GloVe embeddings can improve the identification of named entities in text, such as names of people, organizations, and locations.
-
Text Generation: In creative applications, GloVe can be used in models that generate human-like text, such as poetry or story writing.
Pricing
GloVe is an open-source tool, which means it is free to use. Users can download the GloVe code and pre-trained models from the official repository without any licensing fees. This makes it an attractive option for researchers, developers, and businesses looking to implement word embeddings without incurring additional costs.
While the tool itself is free, users should consider potential costs associated with the infrastructure needed for training on large datasets, especially if they opt to create custom embeddings. These costs may include cloud computing resources, data storage, and any additional software or tools required for data preprocessing and model training.
Comparison with Other Tools
When considering GloVe, it is essential to compare it with other popular word embedding techniques, such as Word2Vec and FastText. Here’s a brief comparison:
| Feature | GloVe | Word2Vec | FastText |
|---|---|---|---|
| Training Method | Global co-occurrence matrix | Predictive (Skip-gram, CBOW) | Subword information (n-grams) |
| Contextualization | Global statistics | Local context | Local context + subword info |
| Pre-trained Models | Available on large datasets | Available on large datasets | Available on large datasets |
| Analogies | Strong support for analogies | Strong support for analogies | Strong support for analogies |
| Language Support | Multilingual training possible | Multilingual training possible | Multilingual training possible |
| Computational Efficiency | Efficient for large datasets | Generally efficient | More computationally intensive |
Key Differences
-
Training Approach: GloVe focuses on global co-occurrence statistics, while Word2Vec relies on local context through predictive modeling. FastText extends Word2Vec by considering subword information, which helps in capturing morphological variations of words.
-
Handling Out-of-Vocabulary Words: FastText has an advantage as it can generate embeddings for out-of-vocabulary words using subword information, while GloVe and Word2Vec cannot generate embeddings for words not seen during training.
-
Performance on Analogy Tasks: GloVe has been shown to perform exceptionally well on analogy tasks, making it a strong choice for applications requiring semantic understanding.
-
Ease of Use: All three tools are relatively easy to implement, but GloVe’s straightforward approach to generating embeddings from a co-occurrence matrix can be appealing for users looking for simplicity.
FAQ
What kind of data can I use to train GloVe?
GloVe can be trained on any text data, including articles, books, and social media posts. The quality and size of the dataset will significantly impact the quality of the resulting embeddings.
How do I use pre-trained GloVe models?
Pre-trained GloVe models can be easily downloaded and loaded into your programming environment. You can then use these embeddings as feature vectors for various NLP tasks, such as classification or clustering.
Can I train GloVe on my own dataset?
Yes, GloVe allows users to train embeddings on custom datasets. This is particularly useful for domain-specific applications where general pre-trained embeddings may not capture the nuanced meanings of words.
Is GloVe suitable for real-time applications?
While GloVe is efficient for generating embeddings, real-time applications may require additional optimization. The embeddings themselves can be used in real-time systems, but the training process typically involves significant computational resources.
What are the limitations of GloVe?
Some limitations of GloVe include its inability to handle out-of-vocabulary words and the need for a large corpus to produce high-quality embeddings. Additionally, while GloVe captures semantic relationships well, it may not capture contextual nuances as effectively as models based on deep learning approaches.
How does GloVe handle polysemy (words with multiple meanings)?
GloVe embeddings are based on the overall context in which words appear, which can help to some extent with polysemy. However, since it does not differentiate meanings based on context as effectively as some modern contextual embeddings (like BERT), it may not always capture the nuances of polysemous words.
Can GloVe be used for languages other than English?
Yes, GloVe can be trained on datasets in multiple languages, making it suitable for multilingual applications. However, the quality of the embeddings will depend on the size and quality of the training data in those languages.
In conclusion, GloVe is a powerful and versatile tool for generating word embeddings, offering unique advantages through its global statistical approach. Its ease of use, customizability, and availability of pre-trained models make it a popular choice among researchers and developers in the field of natural language processing. Whether you are working on text classification, information retrieval, or any other NLP task, GloVe provides a robust foundation for understanding and leveraging the semantic relationships between words.
Ready to try it out?
Go to GloVe