
Crawly
Crawly by Diffbot effortlessly extracts structured data from websites, converting it into CSV or JSON format in seconds.
 Tags
Tags
 Useful for
Useful for
- 1.What is Crawly?
- 2.Features
- 2.1.1. Comprehensive Data Extraction
- 2.2.2. User-Friendly Interface
- 2.3.3. Data Formats
- 2.4.4. Fast and Efficient
- 2.5.5. Automated Crawling
- 2.6.6. Scalability
- 2.7.7. Support for Multiple Languages
- 3.Use Cases
- 3.1.1. Market Research
- 3.2.2. Content Aggregation
- 3.3.3. Academic Research
- 3.4.4. SEO Analysis
- 3.5.5. Data Journalism
- 3.6.6. E-commerce Insights
- 4.Pricing
- 4.1.1. Free Trial
- 4.2.2. Pay-As-You-Go
- 4.3.3. Subscription Plans
- 4.4.4. Custom Solutions
- 5.Comparison with Other Tools
- 5.1.1. Ease of Use
- 5.2.2. Automation
- 5.3.3. Comprehensive Data Extraction
- 5.4.4. Speed and Efficiency
- 5.5.5. Scalability
- 6.FAQ
- 6.1.Q1: Is Crawly suitable for beginners?
- 6.2.Q2: Can I use Crawly to extract data from any website?
- 6.3.Q3: What formats can I download the extracted data in?
- 6.4.Q4: Is there a free trial available?
- 6.5.Q5: How does Crawly handle data privacy and security?
- 6.6.Q6: Can Crawly be used for large-scale data extraction projects?
What is Crawly?
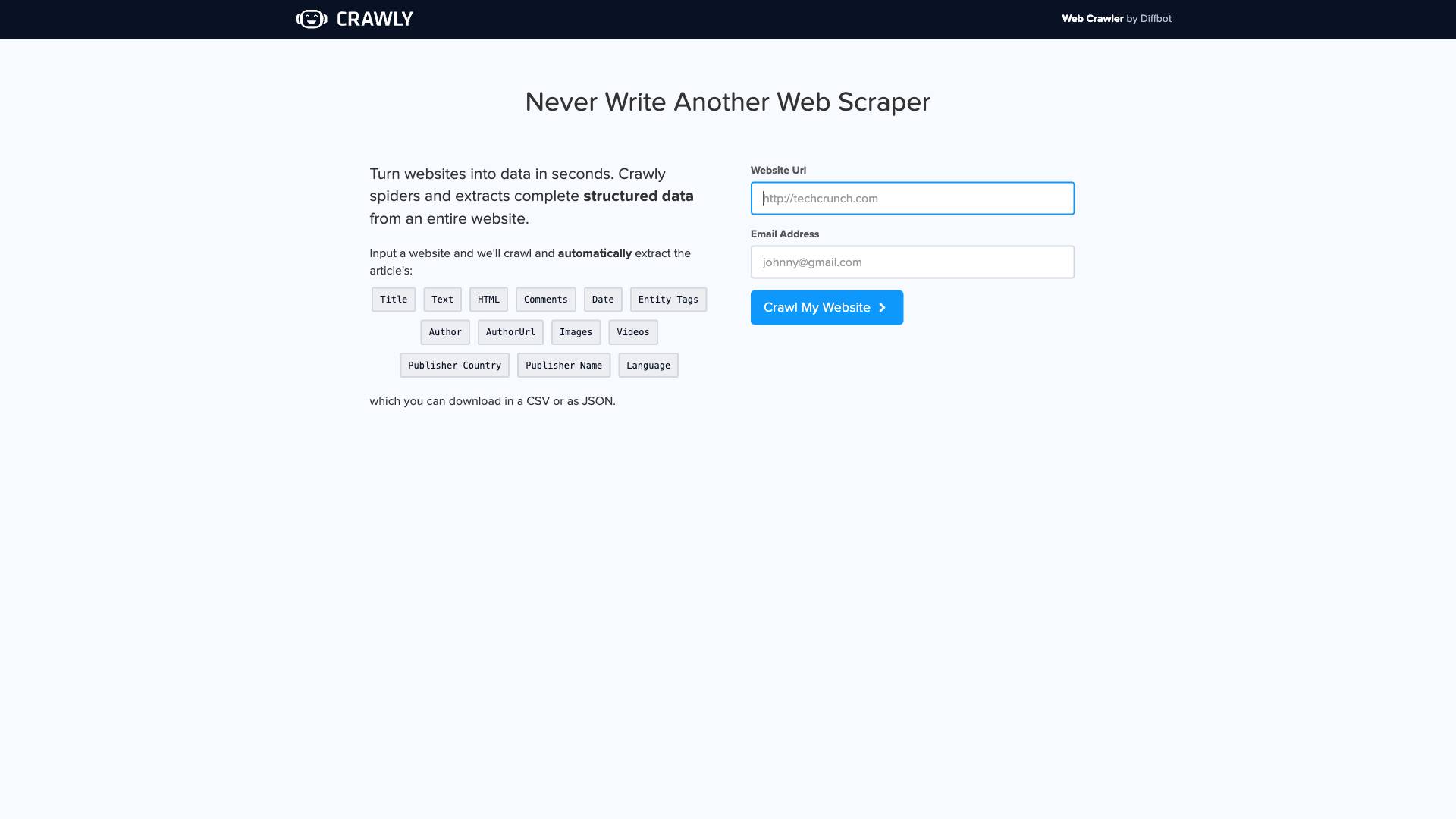
Crawly, developed by Diffbot, is an advanced web crawling and data extraction tool designed to transform websites into structured data effortlessly. It enables users to extract valuable information from various web pages without the need for complex programming or manual scraping. With Crawly, users can input a website URL, and the tool will automatically spider the site, extracting key components such as article titles, text, images, videos, and more. This makes it an invaluable resource for businesses, researchers, and developers looking to gather data quickly and efficiently.
Features
Crawly comes packed with a variety of features that enhance its usability and effectiveness. Here are some of the standout features:
1. Comprehensive Data Extraction
Crawly extracts a wide range of data points from websites, including:
- Title: The main title of the article or page.
- Text: The main body content of the article.
- HTML: The raw HTML content for further processing.
- Comments: User comments associated with the article.
- Date: The publication date of the article.
- Entity Tags: Tags that categorize the content.
- Author: Information about the author of the article.
- Author URL: A link to the author's profile or page.
- Images: Extracted images from the article.
- Videos: Embedded videos related to the content.
- Publisher Country: The country where the publisher is located.
- Publisher Name: The name of the publishing entity.
- Language: The language in which the content is written.
2. User-Friendly Interface
Crawly features an intuitive and user-friendly interface, making it accessible for users with varying levels of technical expertise. The straightforward design allows users to input a website URL and initiate the crawling process with minimal effort.
3. Data Formats
Once the data extraction process is complete, users can download the structured data in popular formats such as CSV or JSON. This flexibility ensures that the data can be easily integrated into various applications or databases for further analysis.
4. Fast and Efficient
Crawly is designed to perform web crawling and data extraction quickly. Users can expect to receive their data in seconds, allowing for rapid decision-making and analysis.
5. Automated Crawling
The tool automates the entire crawling process, eliminating the need for manual scraping. This feature not only saves time but also reduces the potential for errors that may occur during manual data extraction.
6. Scalability
Crawly is scalable, making it suitable for both small projects and large-scale data extraction tasks. Whether you need to extract data from a single page or an entire website, Crawly can handle the workload efficiently.
7. Support for Multiple Languages
Crawly supports data extraction from websites in various languages, making it a versatile tool for global users. This feature is particularly beneficial for businesses operating in multiple regions or researchers studying content across different languages.
Use Cases
Crawly can be utilized in a variety of scenarios, catering to different industries and user needs. Here are some common use cases:
1. Market Research
Businesses can leverage Crawly to gather data on competitors, industry trends, and customer preferences. By extracting information from competitor websites, companies can analyze product offerings, pricing strategies, and customer feedback.
2. Content Aggregation
Content creators and bloggers can use Crawly to aggregate relevant articles and data from multiple sources. This allows them to curate content for newsletters, blogs, or social media posts efficiently.
3. Academic Research
Researchers can utilize Crawly to collect data for academic studies. By extracting information from various sources, they can analyze trends, gather statistics, and support their findings with real-world data.
4. SEO Analysis
SEO professionals can use Crawly to extract data from websites to analyze keyword usage, content structure, and backlink profiles. This information can help in optimizing their own websites for better search engine rankings.
5. Data Journalism
Journalists can employ Crawly to gather data for investigative reports. By extracting information from multiple sources, they can create comprehensive stories backed by solid data.
6. E-commerce Insights
E-commerce businesses can use Crawly to monitor product listings, prices, and customer reviews from competitors. This data can inform pricing strategies and product development.
Pricing
Crawly offers a range of pricing options to accommodate different user needs. While specific pricing details may vary, the tool typically provides tiered plans based on the volume of data extracted or the number of websites crawled. Here’s an overview of potential pricing structures:
1. Free Trial
Crawly may offer a free trial period, allowing users to test the tool's features and capabilities before committing to a paid plan. This is an excellent opportunity for users to evaluate the tool’s effectiveness for their specific needs.
2. Pay-As-You-Go
This pricing model allows users to pay for the data they extract on a per-use basis. This option is ideal for users who need occasional access to the tool without a long-term commitment.
3. Subscription Plans
Crawly may offer subscription-based pricing, where users can choose from different tiers based on their data extraction needs. Higher-tier plans typically provide additional features, higher data limits, and priority support.
4. Custom Solutions
For businesses with unique requirements, Crawly may offer custom solutions tailored to specific data extraction needs. This could include dedicated support or specialized features.
Comparison with Other Tools
When evaluating Crawly against other web scraping and data extraction tools, several factors set it apart from the competition. Here’s how Crawly compares with other popular tools in the market:
1. Ease of Use
Crawly’s user-friendly interface makes it more accessible than many other tools that require technical knowledge or coding skills. Users can start extracting data with minimal setup, unlike some alternatives that may involve complex configurations.
2. Automation
Crawly automates the data extraction process, reducing the manual effort required. While other tools may offer automation features, Crawly’s seamless integration of automation simplifies the user experience significantly.
3. Comprehensive Data Extraction
Crawly excels in its ability to extract a wide range of data points from websites. While some tools focus on specific data types, Crawly covers a broader spectrum, making it a more versatile option for users with diverse needs.
4. Speed and Efficiency
Crawly is designed for quick data extraction, often delivering results in seconds. This speed is a significant advantage over other tools that may take longer to process and extract data.
5. Scalability
Crawly’s scalability allows it to cater to a wide range of users, from individuals needing occasional data extraction to large organizations requiring extensive data scraping. This flexibility is not always present in other tools.
FAQ
Q1: Is Crawly suitable for beginners?
Yes, Crawly is designed with a user-friendly interface, making it suitable for users with varying levels of technical expertise. Beginners can easily navigate the tool and start extracting data without prior experience.
Q2: Can I use Crawly to extract data from any website?
Crawly can extract data from most websites, but some sites may have restrictions or anti-scraping measures in place. It’s essential to review the website’s terms of service and ensure compliance with legal guidelines when using Crawly.
Q3: What formats can I download the extracted data in?
Crawly allows users to download extracted data in popular formats such as CSV and JSON, making it easy to integrate the data into various applications or databases.
Q4: Is there a free trial available?
Crawly may offer a free trial period, allowing users to test the tool’s features before committing to a paid plan. Check the official website for specific details regarding trial availability.
Q5: How does Crawly handle data privacy and security?
Crawly adheres to best practices for data privacy and security. Users should ensure they comply with legal regulations when extracting data from websites, and Crawly provides guidelines to help users navigate these considerations.
Q6: Can Crawly be used for large-scale data extraction projects?
Yes, Crawly is scalable and can handle large-scale data extraction projects efficiently. Users can choose from different pricing plans based on their data extraction needs, making it suitable for both small and large projects.
In conclusion, Crawly by Diffbot is a powerful and versatile web crawling and data extraction tool that simplifies the process of gathering structured data from websites. Its comprehensive features, user-friendly interface, and rapid data extraction capabilities make it an ideal choice for businesses, researchers, and content creators alike. With its various use cases and competitive pricing, Crawly stands out as a valuable resource in the realm of web scraping and data extraction.
Ready to try it out?
Go to Crawly