
Apache Spark ML
Apache Spark MLlib is a scalable machine learning library that integrates seamlessly with Spark, offering high-quality algorithms for fast, iterative computations.
 Tags
Tags
 Useful for
Useful for
- 1.What is Apache Spark ML?
- 1.1.Features
- 1.1.1.1. Ease of Use
- 1.1.2.2. Performance
- 1.1.3.3. Versatile Data Handling
- 1.1.4.4. Comprehensive Algorithm Library
- 1.1.5.5. ML Workflow Utilities
- 1.1.6.6. Additional Utilities
- 1.1.7.7. Community and Support
- 1.2.Use Cases
- 1.2.1.1. Fraud Detection
- 1.2.2.2. Recommendation Systems
- 1.2.3.3. Customer Segmentation
- 1.2.4.4. Sentiment Analysis
- 1.2.5.5. Predictive Maintenance
- 1.2.6.6. Healthcare Analytics
- 1.3.Pricing
- 1.4.Comparison with Other Tools
- 1.4.1.1. Scalability
- 1.4.2.2. Integration with Big Data Ecosystems
- 1.4.3.3. Performance
- 1.4.4.4. Unified Framework
- 1.4.5.5. Rich Algorithm Library
- 1.4.6.6. Community and Support
- 1.5.FAQ
- 1.5.1.1. What programming languages does Apache Spark ML support?
- 1.5.2.2. Can I use Apache Spark ML with my existing Hadoop setup?
- 1.5.3.3. Is Apache Spark ML suitable for real-time machine learning applications?
- 1.5.4.4. How does MLlib ensure performance optimization?
- 1.5.5.5. Can I contribute to Apache Spark ML?
- 1.5.6.6. What are the system requirements for running Apache Spark ML?
- 1.5.7.7. Where can I find documentation and support for Apache Spark ML?
What is Apache Spark ML?
Apache Spark ML, commonly referred to as MLlib, is a scalable machine learning library designed to integrate seamlessly with the Apache Spark ecosystem. It provides a rich set of machine learning algorithms and utilities that can handle large-scale data processing and analysis. MLlib is built on top of the Spark framework, allowing for distributed computing, which significantly enhances performance and efficiency. With support for multiple programming languages, including Java, Scala, Python, and R, MLlib makes it easier for developers and data scientists to implement machine learning models and workflows.
Features
Apache Spark ML is packed with features that make it a powerful tool for machine learning. Here are some of the key features:
1. Ease of Use
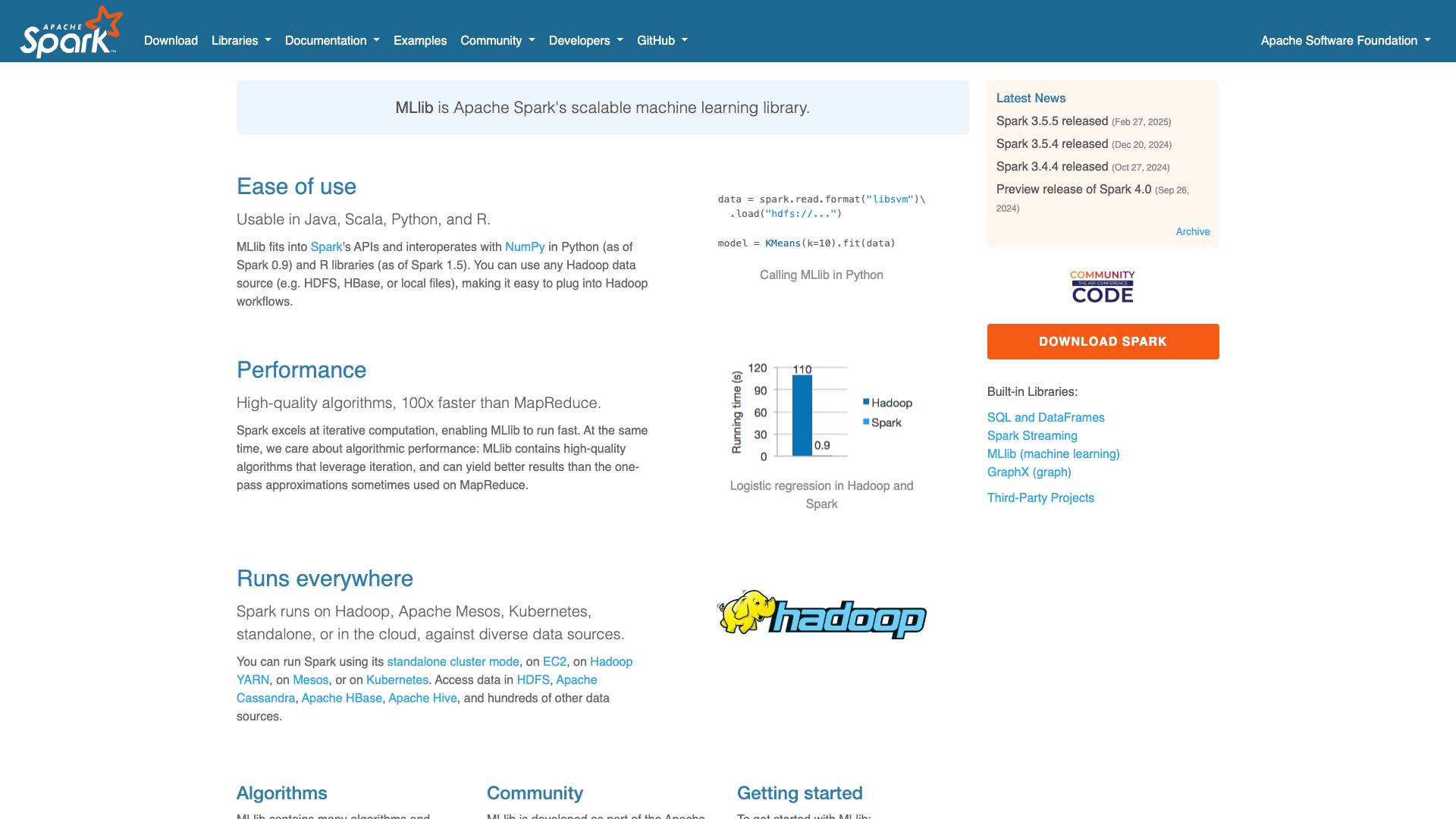
- Multi-Language Support: MLlib is usable in Java, Scala, Python, and R, making it accessible to a wide range of developers and data scientists.
- Integration with Spark APIs: MLlib fits naturally into Spark's APIs, allowing users to leverage existing Spark functionalities and seamlessly work with data.
2. Performance
- High-Quality Algorithms: MLlib boasts a collection of high-quality machine learning algorithms that are optimized for performance.
- Speed: The library is reported to be up to 100 times faster than traditional MapReduce implementations, thanks to Spark's efficient in-memory computing capabilities.
3. Versatile Data Handling
- Data Source Compatibility: MLlib can easily connect to any Hadoop data source, such as HDFS, HBase, or local files, making it suitable for various data workflows.
- Support for Diverse Data Sources: In addition to Hadoop, MLlib can access data from systems like Apache Cassandra, Apache Hive, and more.
4. Comprehensive Algorithm Library
MLlib includes a wide array of algorithms and utilities, categorized as follows:
- Classification: Logistic regression, naive Bayes, decision trees, and random forests.
- Regression: Generalized linear regression and survival regression.
- Clustering: K-means, Gaussian mixtures, and hierarchical clustering.
- Recommendation: Alternating least squares (ALS) for collaborative filtering.
- Topic Modeling: Latent Dirichlet allocation (LDA).
- Association Rules: Frequent itemsets and sequential pattern mining.
5. ML Workflow Utilities
- Feature Transformations: Includes operations like standardization, normalization, and hashing to preprocess data.
- ML Pipeline Construction: Facilitates the construction of machine learning workflows, enabling users to chain multiple algorithms and transformations.
- Model Evaluation and Hyper-Parameter Tuning: Tools for assessing model performance and optimizing parameters.
6. Additional Utilities
- Distributed Linear Algebra: Operations such as Singular Value Decomposition (SVD) and Principal Component Analysis (PCA) for advanced data analysis.
- Statistical Functions: Summary statistics and hypothesis testing features for data exploration and validation.
7. Community and Support
- Active Development: MLlib is continuously updated and tested as part of the Apache Spark project, ensuring users have access to the latest features and improvements.
- Community Contributions: The library encourages community involvement, allowing users to contribute algorithms and enhancements.
Use Cases
Apache Spark ML is versatile and can be applied to various domains and industries. Here are some common use cases:
1. Fraud Detection
Financial institutions can utilize MLlib to build models that identify fraudulent transactions based on historical data patterns, helping to minimize losses and enhance security.
2. Recommendation Systems
E-commerce platforms can leverage collaborative filtering algorithms, such as ALS, to provide personalized product recommendations to users based on their past behavior and preferences.
3. Customer Segmentation
Businesses can analyze customer data using classification and clustering algorithms to segment their audience, allowing for targeted marketing strategies and improved customer engagement.
4. Sentiment Analysis
Organizations can employ natural language processing techniques available in MLlib to analyze customer feedback and social media data, gaining insights into public sentiment towards their products or services.
5. Predictive Maintenance
Manufacturers can use regression models to predict equipment failures based on historical maintenance data, enabling proactive maintenance and reducing downtime.
6. Healthcare Analytics
MLlib can assist healthcare providers in analyzing patient data to identify trends, predict disease outbreaks, and tailor treatment plans based on individual patient profiles.
Pricing
Apache Spark ML is part of the Apache Spark ecosystem, which is an open-source project. As such, it is free to use, download, and modify under the Apache License, Version 2.0. Organizations can deploy Spark and MLlib on their own infrastructure or leverage cloud services that support Spark, such as AWS, Google Cloud, or Azure. While the software itself is free, users may incur costs associated with cloud infrastructure, data storage, and additional services.
Comparison with Other Tools
When comparing Apache Spark ML with other machine learning frameworks and libraries, several unique selling points emerge:
1. Scalability
- Spark ML is designed for distributed computing, allowing it to handle massive datasets that may be challenging for other libraries like Scikit-Learn or TensorFlow when running on a single machine.
2. Integration with Big Data Ecosystems
- Unlike many standalone machine learning libraries, Spark ML integrates effectively with big data tools and platforms, such as Hadoop, making it ideal for organizations already invested in these ecosystems.
3. Performance
- Spark’s in-memory processing capabilities lead to faster execution times compared to traditional batch processing frameworks, making MLlib a preferred choice for iterative machine learning tasks.
4. Unified Framework
- Spark provides a unified framework that combines batch processing, streaming, and machine learning, allowing users to build comprehensive data processing pipelines without needing to switch between different tools.
5. Rich Algorithm Library
- While many libraries focus on specific types of algorithms, Spark ML offers a broad range of machine learning techniques, making it suitable for various applications.
6. Community and Support
- As part of the Apache Software Foundation, Spark ML benefits from a large and active community, providing users with access to extensive documentation, forums, and contributions from other developers.
FAQ
1. What programming languages does Apache Spark ML support?
Apache Spark ML supports Java, Scala, Python, and R, making it accessible to a broad range of developers.
2. Can I use Apache Spark ML with my existing Hadoop setup?
Yes, Apache Spark ML can easily integrate with existing Hadoop setups and can access data from various Hadoop data sources like HDFS and HBase.
3. Is Apache Spark ML suitable for real-time machine learning applications?
Yes, Spark ML can be used for real-time machine learning applications, especially when combined with Spark Streaming for processing live data streams.
4. How does MLlib ensure performance optimization?
MLlib is optimized for performance through in-memory computing, efficient algorithm implementations, and the ability to leverage distributed computing resources.
5. Can I contribute to Apache Spark ML?
Absolutely! The Apache Spark community welcomes contributions, and you can submit algorithms or enhancements by following the contribution guidelines provided by the project.
6. What are the system requirements for running Apache Spark ML?
The system requirements depend on the scale of your data and the deployment environment. Spark can run on a single machine or in a distributed cluster, and it is compatible with various operating systems.
7. Where can I find documentation and support for Apache Spark ML?
Documentation, usage examples, and community support can be found through the official Apache Spark project resources, including mailing lists and forums.
In conclusion, Apache Spark ML (MLlib) stands out as a powerful, scalable, and versatile machine learning library that integrates seamlessly with the Apache Spark ecosystem. Its performance, ease of use, and comprehensive set of features make it an attractive choice for data scientists and developers looking to implement machine learning solutions across various industries.
Ready to try it out?
Go to Apache Spark ML